쿠버네티스는 컨테이너를 쉽고 빠르게 배포/확장하고 관리를 자동화해주는 오픈소스 플랫폼이다.
단순한 컨테이너 플랫폼이 아닌 마이크로서비스, 클라우드 플랫폼을 지향하고 컨테이너로 이루어진 것들을 손쉽게 담고 관리할 수 있는 그릇 역할을 합니다. 서버리스, CI/CD, 머신러닝 등 다양한 기능이 쿠버네티스 플랫폼 위에서 동작합니다.
특징
1> ECO System
전 세계적 스케일의 경험과 기술이 고스란히 녹아들어 있습니다. 거대한 커뮤니티와 생태계가 있어 잘 안 되는 건 찾아보면 되고 이런 거 만들어 볼까 하면 누군가 만들어 놨습니다. 서비스메시(Istio, linkerd), CI(Tekton, Spinnaker), 컨테이너 서버리스(Knative), 머신러닝(kubeflow)이 모두 쿠버네티스 환경에서 돌아갑니다. 클라우드 네이티브 애플리케이션 대부분이 쿠버네티스와 찰떡궁합입니다.
2> 다양한 배포 방식
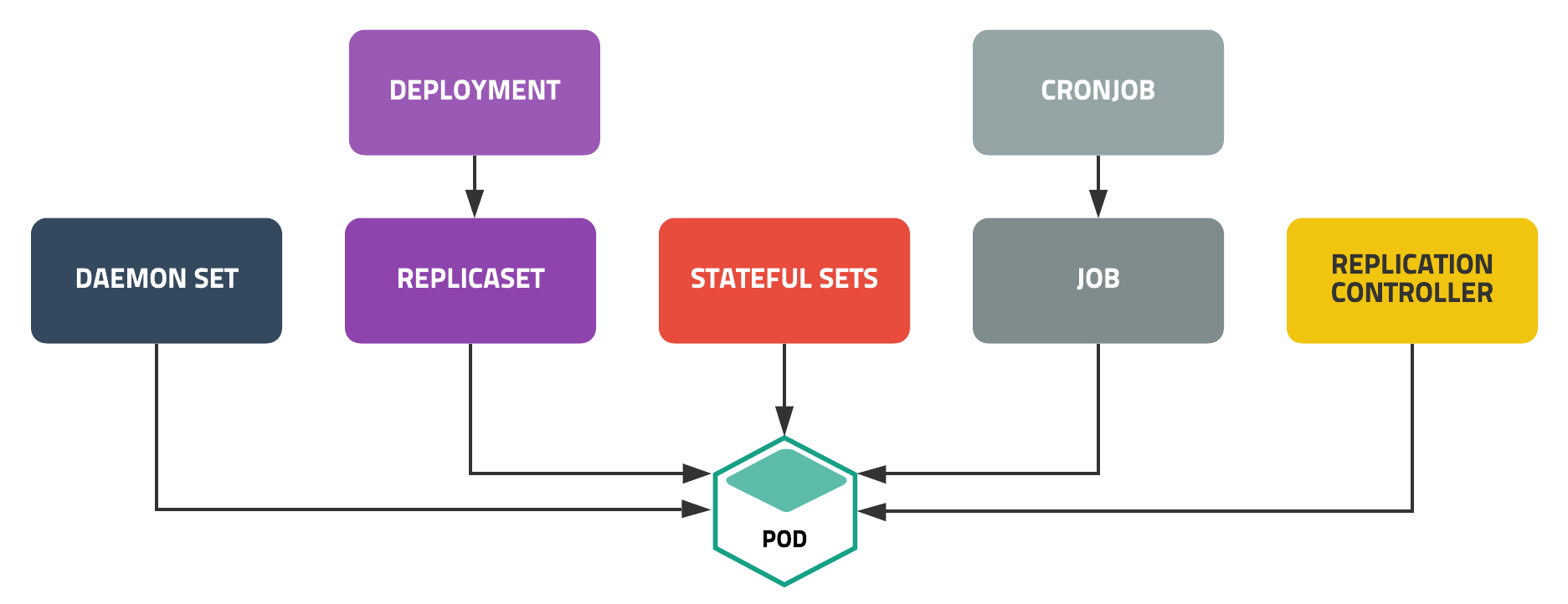
컨테이너와 관련된 많은 예제가 웹(프론트엔드+백엔드) 애플리케이션을 다루고 있지만, 실제 세상엔 더 다양한 형태의 애플리케이션이 있습니다. 쿠버네티스는 Deployment, StatefulSets, DaemonSet, Job, CronJob등 다양한 배포 방식을 지원합니다.
Deployment는 새로운 버전의 애플리케이션을 다양한 전략으로 무중단 배포할 수 있습니다.
StatefulSets은 실행 순서를 보장하고 호스트 이름과 볼륨을 일정하게 사용할 수 있어 순서나 데이터가 중요한 경우에 사용할 수 있습니다.
로그나 모니터링 등 모든 노드에 설치가 필요한 경우엔 DaemonSet을 이용하고
배치성 작업은 Job이나 CronJob을 이용하면 됩니다.
3> Ingress 설정
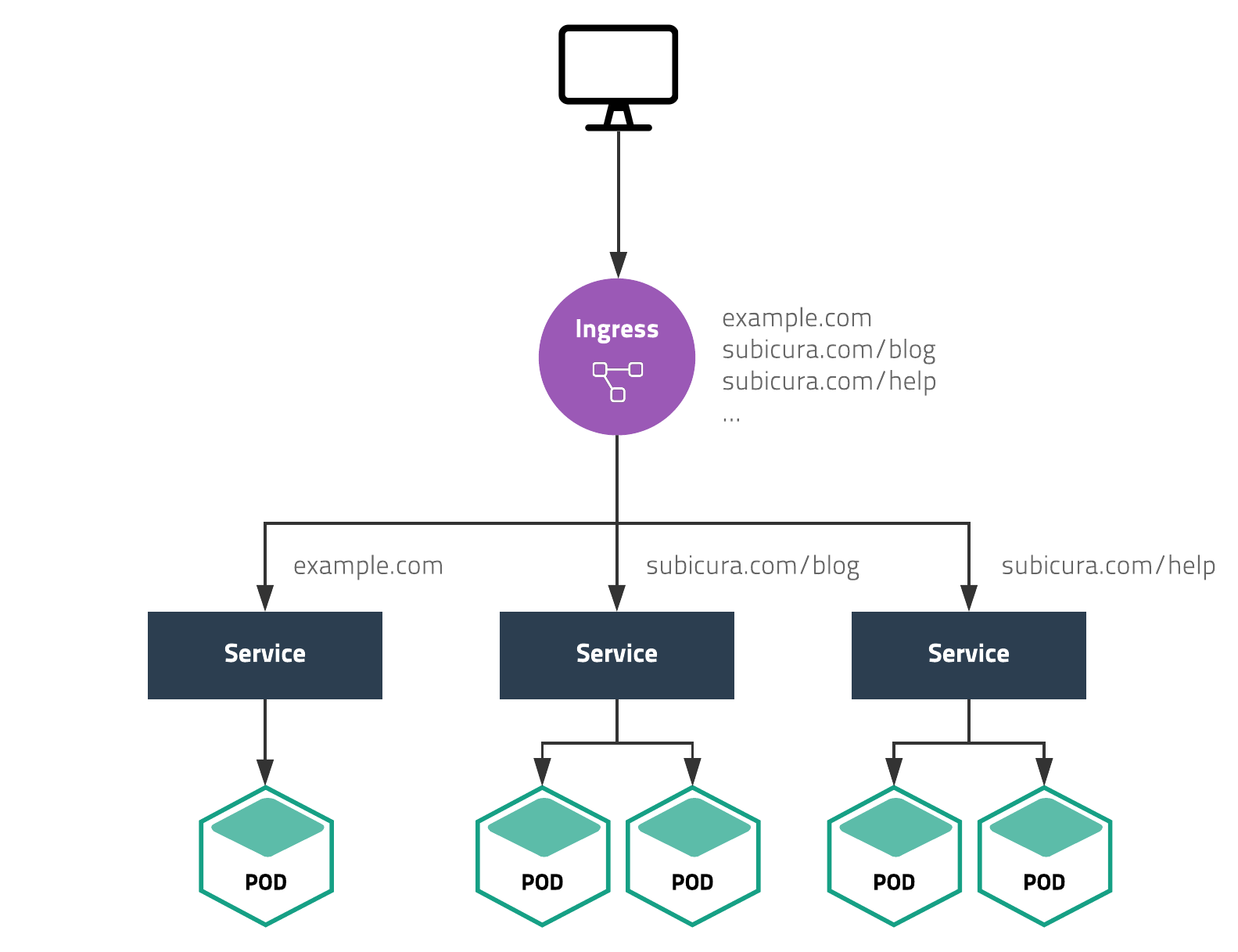
다양한 웹 애플리케이션을 하나의 로드 밸런서로 서비스하기 위해 Ingress기능을 제공합니다.
웹 애플리케이션을 배포하는 과정을 보면 외부에서 직접 접근할 수 없도록 애플리케이션을 내부망에 설치하고 외부에서 접근이 가능한 ALB나 Nginx, Apache를 프록시 서버로 활용합니다. 프록시 서버는 도메인과 Path 조건에 따라 등록된 서버로 요청을 전달하는데 서버가 바뀌거나 IP가 변경되면 매번 설정을 수정해줘야 합니다.
쿠버네티스의 Ingress는 이를 자동화하면서 기존 프록시 서버에서 사용하는 설정을 거의 그대로 사용할 수 있습니다. 새로운 도메인을 추가하거나 업로드 용량을 제한하기 위해 일일이 프록시 서버에 접속하여 설정할 필요가 없습니다.
하나의 클러스터에 여러 개의 Ingress 설정을 할 수 있어 관리자 접속용 Ingress와 일반 접속용 Ingress를 따로 관리할 수 있습니다.
3> Cloud 지원

쿠버네티스는 부하에 따라 자동으로 서버를 늘리는 기능 AutoScaling이 있고 IP를 할당받아 로드밸런스LoadBalancer로 사용할 수 있습니다.
외부 스토리지를 컨테이너 내부 디렉토리에 마운트하여 사용하는 것도 일반적인데 이를 위해 클라우드 별로 적절한 API를 사용하는 모듈이 필요합니다. 쿠버네티스는 Cloud Controller를 이용하여 클라우드 연동을 손쉽게 확장할 수 있습니다. AWS, 구글 클라우드, 마이크로소프트 애저는 물론 수십 개의 클라우드 업체에서 모듈을 제공하여 관리자는 동일한 설정 파일을 서로 다른 클라우드에서 동일하게 사용할 수 있습니다.
4> Namespace & Label
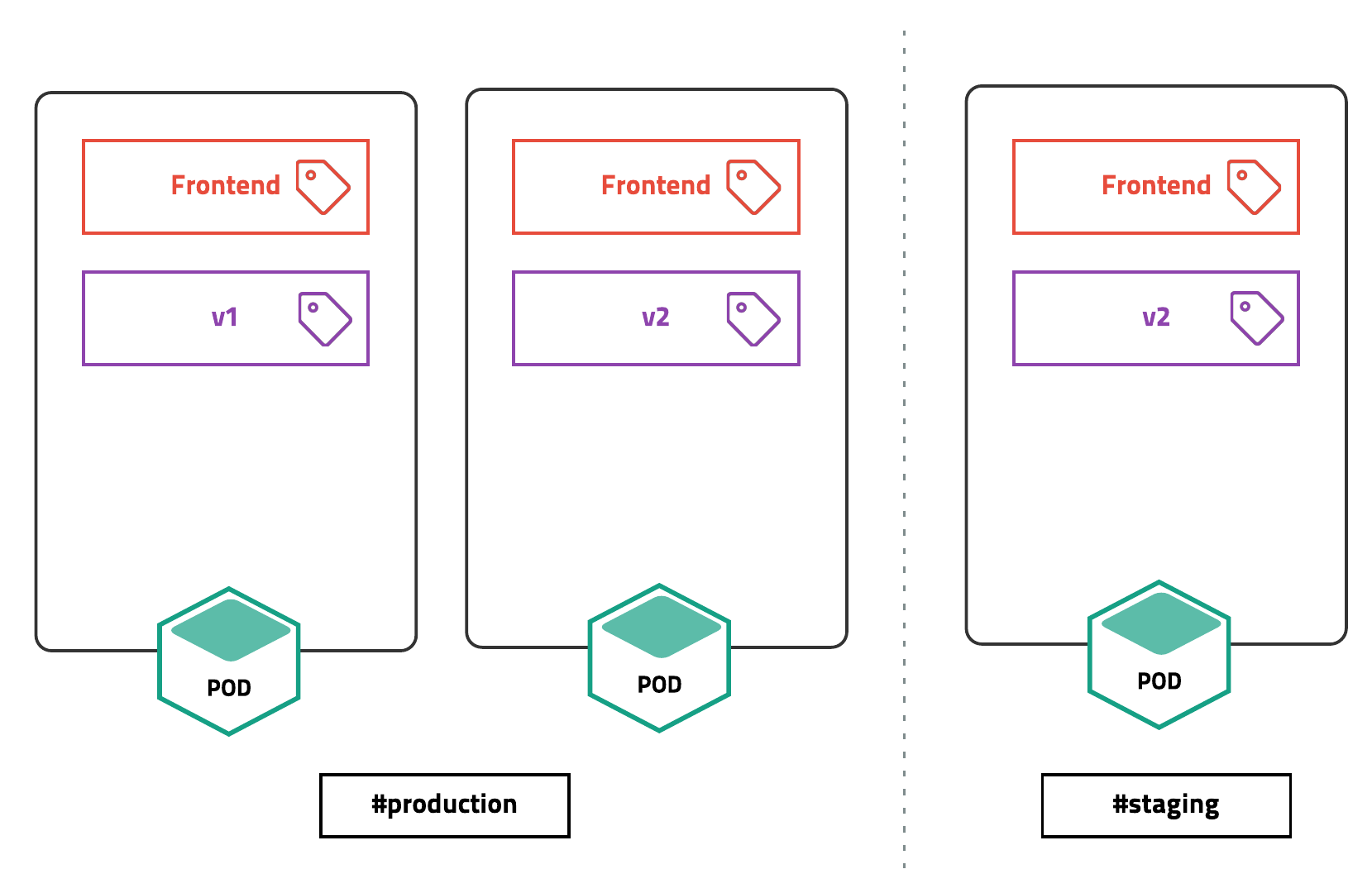
하나의 클러스터를 논리적으로 구분하여 사용할 수 있습니다. 하나의 클러스터에 다양한 프레임워크와 애플리케이션을 설치하기 때문에 기본(system, default)외에 여러 개의 네임스페이스를 사용하는 것이 일반적입니다. 더 세부적인 설정으로 라벨 기능을 적극적으로 사용하여 유연하면서 확장성 있게 리소스를 관리할 수 있습니다.
5> RBAC (role-based access control)
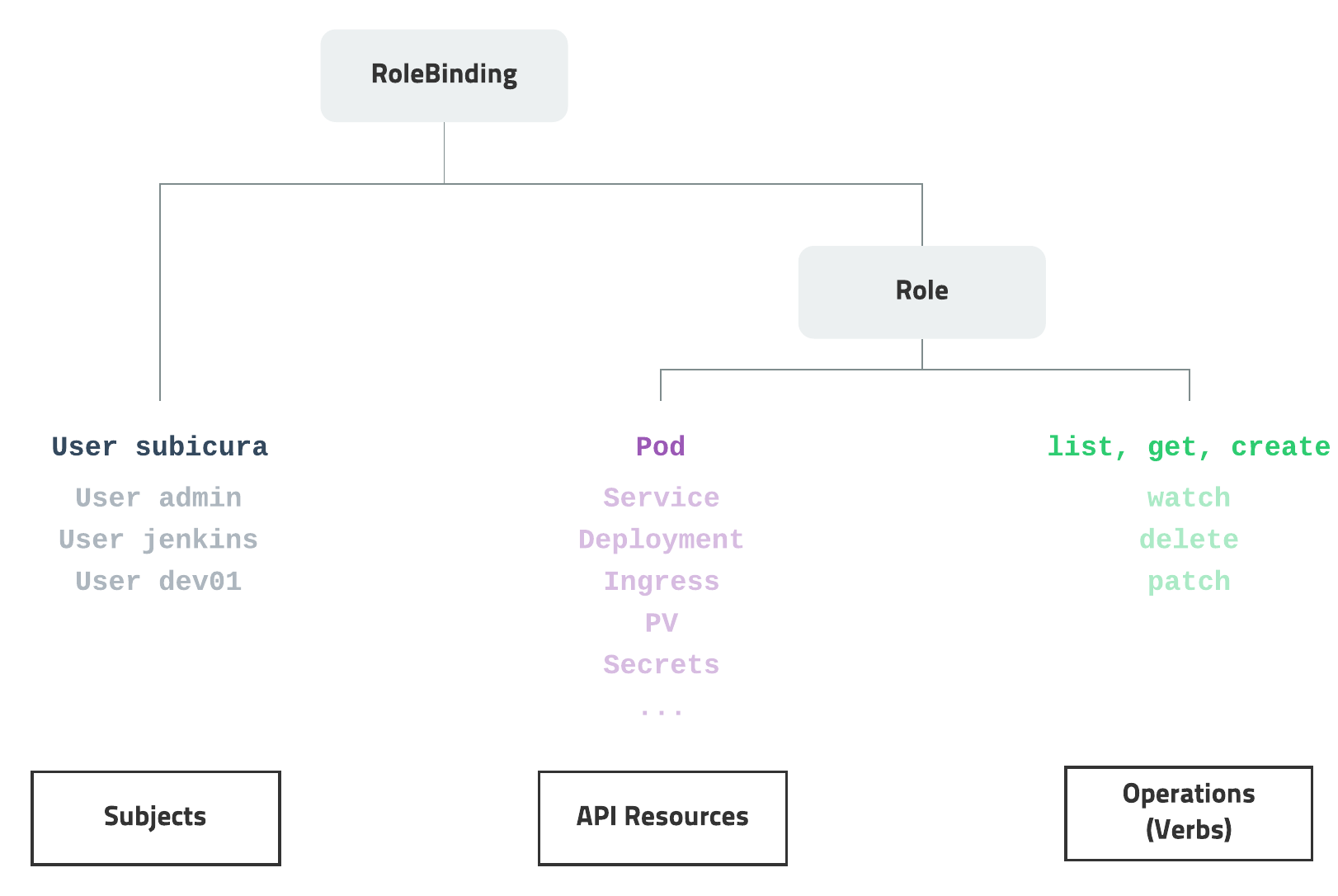
접근 권한 시스템입니다. 각각의 리소스에 대해 유저별로 CRUD스런 권한을 손쉽게 지정할 수 있습니다. 클러스터 전체에 적용하거나 특정 네임스페이스에 적용할 수 있습니다. AWS의 경우 IAM을 연동해서 사용할 수도 있습니다.
6> CRD (Custom Resource Definitaion)
쿠버네티스가 제공하지 않는 기능을 기본 기능과 동일한 방식으로 적용하고 사용할 수 있습니다. 예를 들어, 쿠버네티스는 기본적으로 SSL 인증서 관리 기능을 제공하지 않지만, cert-manager를 설치하고 Certificate 리소스를 이용하면 익숙한 쿠버네티스 명령어로 인증서를 관리할 수 있습니다. 또 다른 도구, 방식을 익힐 필요 없이 다양한 기능을 손쉽게 확장할 수 있습니다.
7> Auto Scaling
CPU, memory 사용량에 따른 확장은 기본이고 현재 접속자 수와 같은 값을 사용할 수도 있습니다. 컨테이너의 개수를 조정하는 Horizontal Pod Autoscaler(HPA), 컨테이너의 리소스 할당량을 조정하는 Vertical Pod Autoscaler(VPA), 서버 개수를 조정하는 Cluster Autosclaer(CA) 방식이 있습니다.
8> Federation, Multi Cluster
클라우드에 설치한 쿠버네티스 클러스터와 자체 서버에 설치한 쿠버네티스를 묶어서 하나로 사용할 수 있습니다. 구글에서 발표한 Anthos를 이용하면 한 곳에서 여러 클라우드의 여러 클러스터를 관리할 수 있습니다.
- 단점
쿠버네티스는 확실히 복잡하고 초반에 개념을 이해하기 어렵습니다. YAML 설정 파일은 너무 많고 클러스터를 만드는 것도 쉽지 않습니다. 하지만 여러 클라우드에서 관리형 서비스를 제공하고 Cloud Code 같은 플러그인을 이용하거나 helm 같은 패키지 매니저를 사용하면 비교적 편리하게 설정파일을 관리할 수 있습니다. 쿠버네티스가 어려운건 이 글에서 최대한 쉽게 설명해 보도록 하겠습니다.
쿠버네티스 기본 개념
쿠버네티스가 어떻게 동작하는지, 설치는 왜 이리 어려운지, 설정 파일은 왜 그렇게 복잡한지 이해하기 위해 쿠버네티스의 디자인과 구성 요소, 각각의 동작 방식을 알아보겠습니다.
Desired State
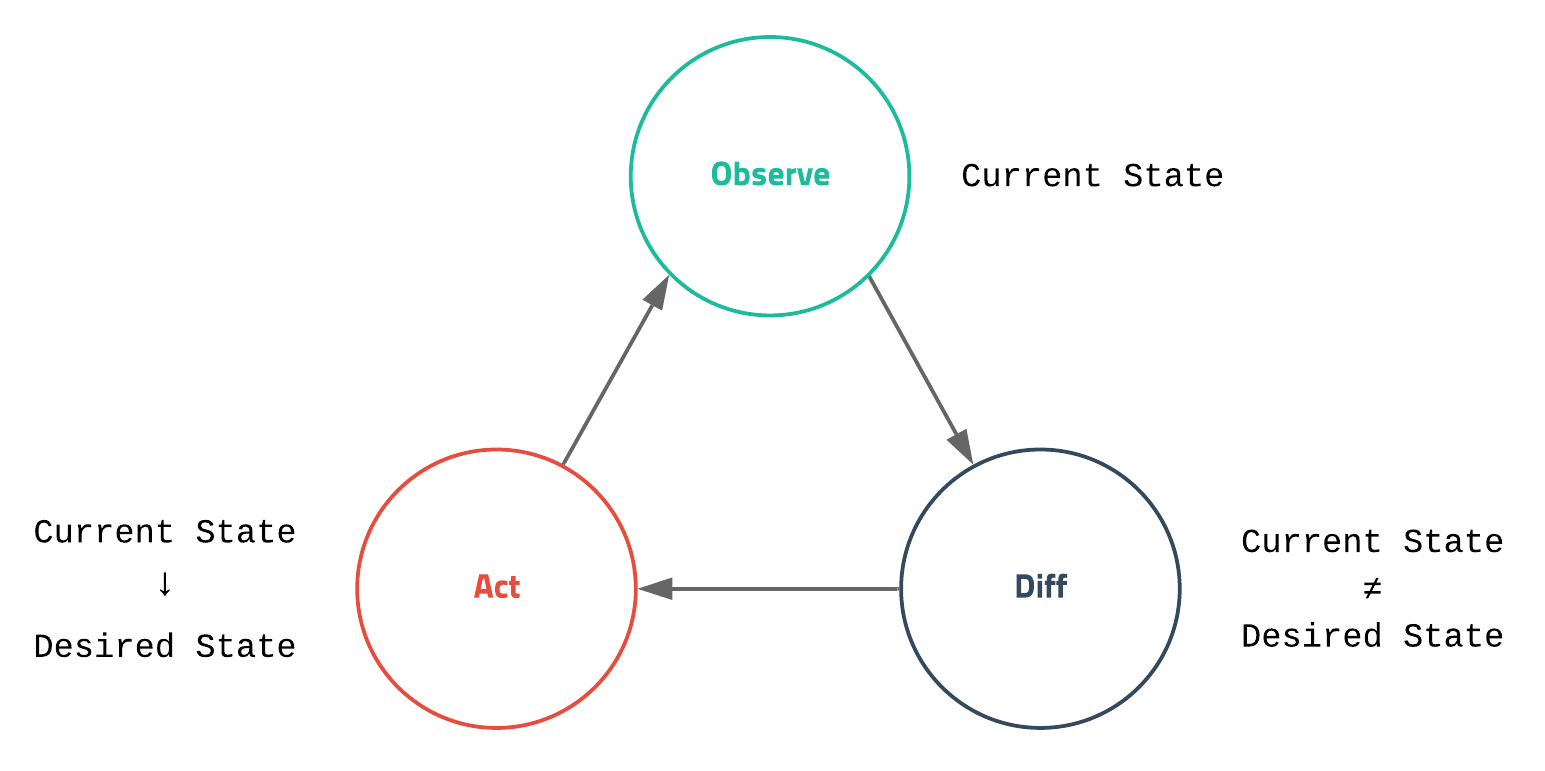
쿠버네티스에서 가장 중요한 것은 desired state - 원하는 상태 라는 개념입니다. 원하는 상태라 함은 관리자가 바라는 환경을 의미하고 좀 더 구체적으로는 얼마나 많은 웹서버가 떠 있으면 좋은지, 몇 번 포트로 서비스하기를 원하는지 등을 말합니다.
쿠버네티스는 복잡하고 다양한 작업을 하지만 자세히 들여다보면 현재 상태current state를 모니터링하면서 관리자가 설정한 원하는 상태를 유지하려고 내부적으로 이런저런 작업을 하는 단순한(?) 로직을 가지고 있습니다.
이러한 개념 때문에 관리자가 서버를 배포할 때 직접적인 동작을 명령하지 않고 상태를 선언하는 방식을 사용합니다. 예를 들어 “nginx 컨테이너를 실행해줘. 그리고 80 포트로 오픈해줘.”는 현재 상태를 원하는 상태로 바꾸기 위한 명령imperative이고 “80 포트를 오픈한 nginx 컨테이너를 1개 유지해줘”는 원하는 상태를 선언declarative 한 것입니다.
언뜻 똑같은 요청을 단어를 살짝 바꿔 말장난하는 게 아닌가 싶은데, 이런 차이는 CLI 명령어에서도 드러납니다.
$ docker run # 명령
$ kubectl create # 상태 생성 (물론 kubectl run 명령어도 있지만 잘 사용하지 않습니다)
쿠버네티스의 핵심은 상태이며 쿠버네티스를 사용하려면 어떤 상태가 있고 어떻게 상태를 선언하는지를 알아야 합니다.
Kubernetes Object
쿠버네티스는 상태를 관리하기 위한 대상을 오브젝트로 정의합니다.
기본으로 수십 가지 오브젝트를 제공하고 새로운 오브젝트를 추가하기가 매우 쉽기 때문에 확장성이 좋습니다. 여러 오브젝트 중 주요 오브젝트는 다음과 같습니다.
- Pod
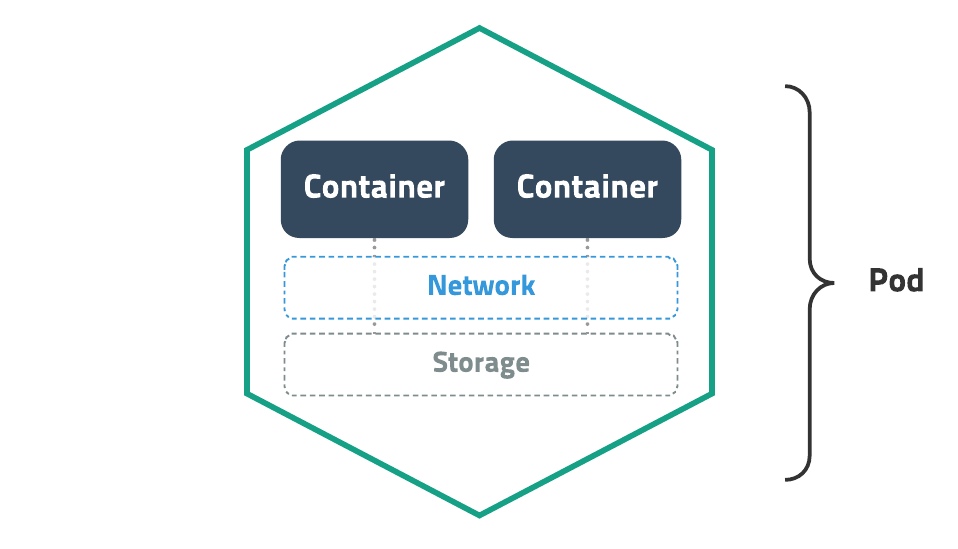
쿠버네티스에서 배포할 수 있는 가장 작은 단위로 한 개 이상의 컨테이너와 스토리지, 네트워크 속성을 가집니다. Pod에 속한 컨테이너는 스토리지와 네트워크를 공유하고 서로 localhost로 접근할 수 있습니다. 컨테이너를 하나만 사용하는 경우도 반드시 Pod으로 감싸서 관리합니다.
- ReplicaSet
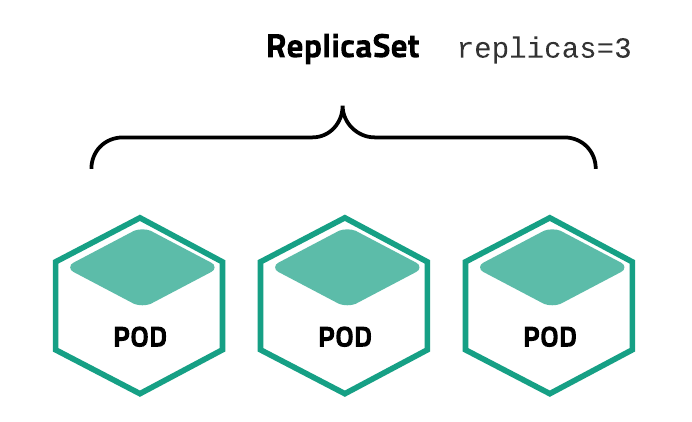
Pod을 여러 개(한 개 이상) 복제하여 관리하는 오브젝트입니다.
Pod을 생성하고 개수를 유지하려면 반드시 ReplicaSet을 사용해야 합니다. ReplicaSet은 복제할 개수, 개수를 체크할 라벨 선택자, 생성할 Pod의 설정값(템플릿)등을 가지고 있습니다.
직접적으로 ReplicaSet을 사용하기보다는 Deployment등 다른 오브젝트에 의해서 사용되는 경우가 많습니다.
- Service
네트워크와 관련된 오브젝트입니다.
Pod을 외부 네트워크와 연결해주고 여러 개의 Pod을 바라보는 내부 로드 밸런서를 생성할 때 사용합니다. 내부 DNS에 서비스 이름을 도메인으로 등록하기 때문에 서비스 디스커버리 역할도 합니다.
- Volume
저장소와 관련된 오브젝트입니다. 호스트 디렉토리를 그대로 사용할 수도 있고 EBS 같은 스토리지를 동적으로 생성하여 사용할 수도 있습니다. 사실상 인기 있는 대부분의 저장 방식을 지원합니다.
- Object Spec - YAML
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
containers:
- name: busybox
image: busybox:1.25
오브젝트의 명세Spec는 YAML 파일(JSON도 가능하다고 하지만 잘 안 씀)로 정의하고 여기에 오브젝트의 종류와 원하는 상태를 입력합니다.
이러한 명세는 생성, 조회, 삭제로 관리할 수 있기 때문에 REST API로 쉽게 노출할 수 있습니다. 접근 권한 설정도 같은 개념을 적용하여 누가 어떤 오브젝트에 어떤 요청을 할 수 있는지 정의할 수 있습니다.
Kubernetes 배포 방식
쿠버네티스는 애플리케이션을 배포하기 위해 원하는 상태(desired state)를 다양한 오브젝트(object)에 라벨Label을 붙여 정의(yaml)하고 API 서버에 전달하는 방식을 사용합니다.
“컨테이너를 2개 배포하고 80 포트로 오픈해줘”라는 간단한 작업을 위해 다음과 같은 구체적인 명령을 전달해야 합니다.
“컨테이너를 Pod으로 감싸고 type=app, app=web이라는 라벨을 달아줘. type=app, app=web이라는 라벨이 달린 Pod이 2개 있는지 체크하고 없으면 Deployment Spec에 정의된 템플릿을 참고해서 Pod을 생성해줘. 그리고 해당 라벨을 가진 Pod을 바라보는 가상의 서비스 IP를 만들고 외부의 80 포트를 방금 만든 서비스 IP랑 연결해줘.”
음.. “정말 뭐 하나 배포할 때마다 저렇게 복잡하게 설정한다고?”라는 의구심이 들 수 있지만 이건 모두 사실입니다. Cloud code, Helm, Knative를 사용하면 조금 편해지긴 하지만 기본적으로 너무 복잡한 편입니다.
다음 포스트에는 쿠버네티스의 개념을 어떻게 구현했는지 구체적인 아키텍처를 살펴보겠습니다.